Introduction
In the fast-paced world of IT infrastructure and system design, ensuring high availability (HA) is a cornerstone of delivering reliable, uninterrupted services. High availability refers to a system's ability to remain operational and accessible for a significant portion of time, minimizing downtime and ensuring that users can rely on it even during unexpected events. Whether you're managing a cloud-based application, a corporate database, or an e-commerce platform, achieving high availability is critical to maintaining customer trust and operational efficiency.
At DumpsQueen, we understand the importance of equipping IT professionals with the knowledge and tools to build robust systems. To ensure high availability, system architects and engineers rely on several design principles that work together to create resilient, fault-tolerant environments. In this comprehensive guide, we’ll explore three key design principles—redundancy, fault tolerance, and scalability—that are essential for ensuring high availability. By delving into each principle, we’ll uncover how they contribute to system reliability and provide actionable insights for implementing them effectively.
Redundancy: Building a Safety Net for Systems
One of the foundational principles for achieving high availability is redundancy. At its core, redundancy involves duplicating critical components or resources within a system so that if one fails, others can seamlessly take over. This approach ensures that there’s no single point of failure (SPOF) that could bring the entire system down. Redundancy can be applied at various levels, from hardware to software to data, and it’s a principle that DumpsQueen emphasizes when preparing IT professionals for real-world challenges.
Imagine a web server hosting an online store. If that server goes offline due to a hardware failure, customers can no longer access the store, leading to lost revenue and damaged reputation. By introducing redundant servers, the system can automatically redirect traffic to a backup server, ensuring uninterrupted service. This concept extends beyond servers to other components like power supplies, network connections, and databases.
In practice, redundancy requires careful planning. For example, in a cloud environment, you might deploy multiple virtual machines across different availability zones. If one zone experiences an outage, the others can continue to handle requests. Similarly, database replication ensures that data is mirrored across multiple locations, so even if one database becomes unavailable, the system can still retrieve data from a replica.
However, redundancy isn’t just about duplicating resources—it’s about ensuring those duplicates are independent and isolated. If two servers are redundant but share the same power source, a single power failure could disable both. At DumpsQueen, we stress the importance of eliminating these dependencies to create truly resilient systems. Redundancy also comes with trade-offs, such as increased costs and complexity, but the benefits of uninterrupted service far outweigh these challenges for mission-critical applications.
By incorporating redundancy into your system design, you create a safety net that protects against hardware failures, network issues, and other disruptions, ensuring that your system remains available to users no matter what.
Fault Tolerance: Embracing Failure as Part of the Design
While redundancy helps prevent failures by duplicating resources, fault tolerance takes a more proactive approach by designing systems to continue functioning even when failures occur. Fault tolerance is about anticipating that things will go wrong—whether it’s a server crash, a software bug, or a network outage—and ensuring the system can handle those failures gracefully. At DumpsQueen, we teach IT professionals that fault tolerance is not about avoiding failure altogether but about building systems that can recover quickly and automatically.
A fault-tolerant system is designed to detect failures and respond without human intervention. For example, consider a distributed database that stores customer information for a banking application. If one node in the database cluster fails, a fault-tolerant design ensures that the system automatically reroutes queries to other nodes, maintaining access to the data. This process happens seamlessly, so users don’t even notice the failure.
Achieving fault tolerance often involves a combination of techniques, such as error detection, failover mechanisms, and self-healing processes. Error detection identifies when something goes wrong, such as a server becoming unresponsive. Failover mechanisms then redirect tasks to backup resources, like switching to a redundant server. Self-healing processes take this a step further by automatically repairing or replacing failed components, such as restarting a crashed application or provisioning a new virtual machine.
At DumpsQueen, we highlight real-world examples to illustrate fault tolerance in action. Take Netflix, for instance, which relies on a highly fault-tolerant architecture to stream content to millions of users. Netflix’s systems are designed to expect and handle failures, using tools like their Chaos Monkey to intentionally introduce faults and test resilience. By adopting similar principles, organizations can ensure their systems remain operational even in the face of unexpected challenges.
Fault tolerance also requires a mindset shift. Instead of striving for perfection, system designers must accept that failures are inevitable and focus on minimizing their impact. This approach not only improves availability but also builds confidence that the system can withstand real-world conditions.
Scalability: Growing to Meet Demand
The third critical design principle for high availability is scalability, which ensures that a system can handle increased demand without compromising performance or availability. In today’s digital landscape, where user traffic can spike unexpectedly—think of Black Friday sales or viral social media campaigns—scalability is non-negotiable. DumpsQueen emphasizes scalability as a key skill for IT professionals, as it directly impacts a system’s ability to remain available under varying workloads.
Scalability comes in two forms: vertical and horizontal. Vertical scalability involves adding more resources to an existing component, such as upgrading a server with more CPU or memory. While this can be effective for smaller systems, it has limits, as there’s only so much power you can add to a single machine. Horizontal scalability, on the other hand, involves adding more components to the system, such as deploying additional servers to distribute the load. This approach is more flexible and aligns with modern cloud architectures.
For example, a scalable e-commerce platform might use a load balancer to distribute incoming traffic across multiple web servers. If traffic surges, the system can automatically spin up additional servers to handle the load, then scale down when demand subsides. This elasticity ensures that the system remains responsive and available, even during peak usage.
Scalability also ties closely to redundancy and fault tolerance. A scalable system with redundant components can redistribute workloads if one component fails, maintaining availability. Similarly, a fault-tolerant design ensures that scaling operations—such as adding new servers—don’t introduce vulnerabilities or downtime.
At DumpsQueen, we encourage IT professionals to think proactively about scalability during the design phase. This means anticipating future growth, choosing technologies that support elastic scaling, and regularly testing the system under heavy loads. Tools like auto-scaling groups in cloud platforms make it easier to implement scalability, but the underlying principle remains the same: a system that can’t grow to meet demand risks becoming unavailable when users need it most.
By prioritizing scalability, organizations can ensure their systems are prepared for both expected and unexpected increases in demand, keeping services accessible and responsive no matter the circumstances.
Balancing the Three Principles for Optimal Availability
While redundancy, fault tolerance, and scalability are powerful on their own, their true impact comes from how they work together. A system with redundancy but no fault tolerance might have backup resources that sit idle during a failure, unable to take over automatically. Similarly, a scalable system without redundancy could struggle to maintain availability if a critical component fails under heavy load. At DumpsQueen, we teach that high availability is about striking a balance between these principles to create a cohesive, resilient architecture.
Consider a cloud-based application serving millions of users. Redundancy ensures that there are multiple servers, databases, and network paths to prevent any single failure from causing downtime. Fault tolerance allows the system to detect and recover from issues, such as rerouting traffic if a server goes offline. Scalability ensures that the system can handle sudden spikes in traffic by adding resources dynamically. Together, these principles create a robust system that delivers consistent availability.
Implementing these principles requires careful planning and ongoing maintenance. System architects must assess the specific needs of their application, considering factors like user expectations, budget constraints, and regulatory requirements. For example, a financial application might prioritize fault tolerance to ensure transactions are never lost, while a streaming service might focus on scalability to handle peak viewing hours. DumpsQueen provides the resources and expertise to help professionals navigate these decisions, ensuring they can design systems that meet real-world demands.
Conclusion
High availability is more than a buzzword—it’s a critical requirement for modern systems that power everything from online businesses to essential services. By focusing on the three design principles of redundancy, fault tolerance, and scalability, IT professionals can build systems that are resilient, responsive, and ready for anything. Redundancy eliminates single points of failure, fault tolerance ensures graceful recovery from issues, and scalability prepares systems for growth and unexpected demand.
At DumpsQueen, we’re committed to helping you master these principles and apply them in real-world scenarios. Whether you’re preparing for a certification exam or designing the next generation of IT infrastructure, understanding how to achieve high availability is a skill that will set you apart. Visit the DumpsQueen to explore our resources, practice questions, and expert guidance, and take the first step toward building systems that users can rely on, no matter what challenges arise.
Free Sample Questions
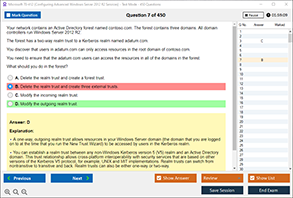
Question 1: Which design principle involves duplicating critical components to eliminate single points of failure?
A) Scalability
B) Fault Tolerance
C) Redundancy
D) Load Balancing
Answer: C) Redundancy
Question 2: What is a key characteristic of a fault-tolerant system?
A) It prevents all failures from occurring.
B) It automatically recovers from failures without human intervention.
C) It scales vertically to handle increased demand.
D) It relies on a single resource to maintain availability.
Answer: B) It automatically recovers from failures without human intervention
Question 3: How does scalability contribute to high availability?
A) By duplicating resources to prevent failures
B) By ensuring the system can handle increased demand without downtime
C) By automatically repairing failed components
D) By isolating failures to a single component
Answer: B) By ensuring the system can handle increased demand without downtime